
3729. 统计有序数组中可被K整除的子数组数量(2025.10.27)#
题目要求[l, r]的对数,使得:
(sum[r] - sum[l - 1]) % k == 0(sum是前缀和)nums[l1, r2] != nums[l2, r2](长度不同或者长度相同内容不同)
因为nums是非降序的,考虑更严苛的条件,一个升序数组,那么第二个条件就没用了,因为所有的子数组必定不相同,再来考虑如果求出满足第一个条件的[l, r]对数:
第一个条件可以转化成sum[r] % k == sum[l - 1] % k
于是可以枚举右端点r,同时在哈希表中记录左端点l(l <= r)的数量,其中key是sum[0, l - 1] % k,然后计算sum[0, r] % k,去哈希表中查有多个左端点满足条件,就能得出右端点为r时有多少个子数组满足条件,总和相加即为答案ans
如果升序数组变为非降序数组,用上面的方法计算会出现一个重复计算的问题,如样例[2, 2, 2, 2, 2, 2]和模值6,但考虑重复计数的情况,两个[l, r]:
- 长度相同
- 内容相同
换句话说,只有在子数组为[x, x, ..., x]这样的形式时才会出现重复计数,那么我们可以统计出来所有这样的子数组,以<x, length>的形式存为一个数组
对于<x, length>这样一个子数组,先前的ans中出现了重复计数,主要原因是相同长度统计了多次,考虑使用m个x能够整除k,即m * x % k == 0,容易使用最小公倍数算出m = lcm(x, k) / x,那么该子数组最少有m + 1个x,才有可能出现重复计数:
-
m个x,重复计数了length - m次 -
2m个x,重复计数了length - 2m次…
令l = length / m(下取整),可以得到子数组<x, length>的重复计数:
repeat_x = l * length - m * (l + 1) * l / 2
使用ans减去每一个repeat_x即为答案
code:
class Solution {
using i64 = long long;
public:
int gcd(int x, int y) {
return y == 0 ? x : gcd(y, x % y);
}
i64 lcm(int x, int y) {
return 1ll * x * y / gcd(x, y);
}
long long numGoodSubarrays(vector<int>& nums, int k) {
i64 ans = 0;
// sum[r] % k == sum[l - 1] % k
unordered_map<i64, int> u_map;
u_map[0] = 1;
i64 sum_r = 0;
int n = nums.size();
for (int i = 0; i < n; i++) {
sum_r = (sum_r + nums[i]) % k;
if (u_map.contains(sum_r)) {
ans += u_map[sum_r];
}
u_map[sum_r]++;
}
// <num, length>
vector<pair<int, int>> total;
int num = nums[0], cnt = 0;
for (int i = 0; i < n; i++) {
if (nums[i] == num) {
cnt++;
} else {
total.push_back({num, cnt});
num = nums[i];
cnt = 1;
}
if (i == n - 1) {
total.push_back({num, cnt});
}
}
i64 repeat = 0;
for (int i = 0; i < total.size(); i++) {
i64 m = lcm(total[i].first, k) / total[i].first;
i64 l = total[i].second / m;
repeat += l * total[i].second - (m * l * (l + 1) / 2);
}
ans -= repeat;
return ans;
}
};时间复杂度:,其中是计算最小公约数的时间
3728. 边界与内部和相等的稳定子数组(2025.10.26)#
求子数组的数量,以下能用,以上就是或者的做法,根据经验,多数与差分,前缀和有关(双指针只是在这个过程用到的技巧),从前缀和的角度去考虑两端的数l和r,找到l和r的关系后,枚举一端(通常是r),同时移动另一端使其满足先前的关系
以问题为例,长度至少为3,首尾元素需相等,中间元素的和需要等于首元素,假设已经有前缀和,那么上面的条件如下:
r - l + 1 >= 3capacity[l] == capacity[r]sum[r - 1] - sum[l] == capacity[l]
将最后一个式子变形得:sum[r - 1] == sum[l] + capacity[l]
于是可以在枚举r时,同时记录{capacity[l], sum[l] + capacity[l]}的数量(使用map),在满足r - l + 1 >= 3的情况下,搜索记录{capacity[r], sum[r - 1]}
如果之前记录的左端被记录过,说明是对于当前r来说,满足以上三个条件的左端点,就可以累加,累加的结果就是答案
code:
class Solution {
public:
long long countStableSubarrays(vector<int>& capacity) {
using i64 = long long;
int n = capacity.size();
i64 sum_l = 0, sum_r = 0;
sum_r += capacity[0] + capacity[1];
map<pair<i64, i64>, i64> map;
i64 ans = 0;
for (int r = 2, l = 0; r < n; r++) {
while (r - l + 1 >= 3) {
sum_l += capacity[l];
pair<i64, i64> index {capacity[l], capacity[l] + sum_l};
map[index]++;
l++;
}
pair<i64, i64> index {capacity[r], sum_r};
sum_r += capacity[r];
if (map.contains(index)) {
ans += map[index];
}
}
return ans;
}
};时间复杂度:
3347. 执行操作后元素的最高频率 II(2025.10.22)#
本题相对3346,扩大了的范围,这使得无法暴力枚举来求出答案,但通过观察可以发现,中并不是所有的数字都值得被枚举,这一点可以通过差分来证明:
对于每一个,其能够转为的数字在之间,考虑一个数轴,这表示在这段数字上+1(代表这段数字可以由操作后得到),如下图所示:
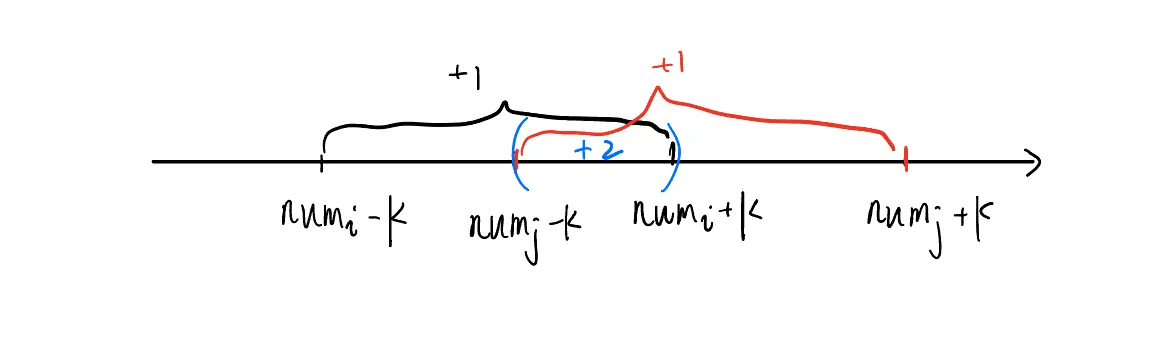
从图中可以看出,只需要枚举,枚举区间上的其他数字,其值不会超过枚举这三个数字得到的值,因此可以缩减枚举的区间,从到所有的,同样使用滑动窗口来遍历原数组,做法和3346相同
code:
class Solution {
public:
using i64 = long long;
int maxFrequency(vector<int>& nums, int k, int numOperations) {
sort(nums.begin(), nums.end());
using PII = pair<int, int>;
vector<PII> u_nums;
int num = nums[0], cnt = 1;
int n = nums.size();
for (int i = 1; i < n; i++) {
if (nums[i] != num) {
u_nums.push_back({num, cnt});
num = nums[i];
cnt = 1;
} else {
cnt++;
}
}
u_nums.push_back({num, cnt});
vector<int> candidate;
n = u_nums.size();
for (int i = 0; i < n; i++) {
candidate.push_back(u_nums[i].first - k);
candidate.push_back(u_nums[i].first);
candidate.push_back(u_nums[i].first + k);
}
sort(candidate.begin(), candidate.end());
n = candidate.size();
queue<int> q;
int sum = 0, ans = 0;
for (int s = 0, i = 0, j = 0; s < n; s++) {
i64 l = 1ll * candidate[s] - k, r = 1ll * candidate[s] + k;
while (!q.empty() && u_nums[q.front()].first < l) {
int index = q.front();
q.pop();
sum -= u_nums[index].second;
}
while (j < u_nums.size() && u_nums[j].first <= r) {
q.push(j);
sum += u_nums[j].second;
j++;
}
if (i < u_nums.size() && candidate[s] == u_nums[i].first) {
int op = min(sum - u_nums[i].second, numOperations);
ans = max(ans, op + u_nums[i].second);
i++;
} else {
int op = min(sum, numOperations);
ans = max(ans, op);
}
}
return ans;
}
};时间复杂度:,是数组长度
3346. 执行操作后元素的最高频率 I(2025.10.21)#
题目中声明所有数字最多被操作一次,考虑到数据量较小,频率最高的数字的范围只可能在,这不难证明,如果操作能使得频率最高的超出这个范围设为,那么在范围内一定存在一个数,使得的频率和相等,题目只要求求出最大的频率,那么这个范围自然是越小越好
那么可以考虑枚举当中的每一个数,则能够通过操作变为的数字范围就在,只需要去原数组中查找这个范围的数有多少个即可
- 对原数组排序
- 对原数组去重,并统计相同数字的数量
- 在遍历中,使用滑动窗口同步滑动处理后的数组,将滑动窗口内的数组限制在中,统计滑动窗口内的数字数量,代表有多少个数字可以转成,然后和可操作数量取最小值,代表可以有个数字可以转成,再比较每个中的最大值
需要注意的是,如果在原数组中出现过,需要额外处理,因为原数组中的这些数字不再需要操作变成
code:
class Solution {
public:
int maxFrequency(vector<int>& nums, int k, int numOperations) {
sort(nums.begin(), nums.end());
using PII = pair<int, int>;
vector<PII> u_nums;
int num = nums[0], cnt = 1;
int n = nums.size();
for (int i = 1; i < n; i++) {
if (nums[i] != num) {
u_nums.push_back({num, cnt});
num = nums[i];
cnt = 1;
} else {
cnt++;
}
}
u_nums.push_back({num, cnt});
int sum = 0, ans = 0;
n = u_nums.size();
queue<int> q;
int s = u_nums[0].first, e = u_nums[n - 1].first;
for (int i = 0, j = 0; s <= e; s++) {
int l = s - k, r = s + k;
// [l, r]
while (!q.empty() && u_nums[q.front()].first < l) {
int index = q.front();
q.pop();
sum -= u_nums[index].second;
}
while (j < n && u_nums[j].first <= r) {
q.push(j);
sum += u_nums[j].second;
j++;
}
if (i < n && s == u_nums[i].first) {
int op = min(sum - u_nums[i].second, numOperations);
ans = max(ans, u_nums[i].second + op);
i += 1;
} else {
int op = min(sum, numOperations);
ans = max(ans, op);
}
}
return ans;
}
};时间复杂度:,是数组大小,是数组中取值范围
1625. 执行操作后字典序最小的字符串(2025.10.19)#
将字符串考虑为图中的一个结点
当进行累加操作时,字符串x变为字符串y,代表从x设置一条有向边指向y
同理,进行轮转操作时,字符串u变为w,代表从u设置一条有向边指向w
那么就可以通过遍历整个图来找到初始字符串可以转换成的所有字符串,然后返回其中字典序最小的一个即可
code:
class Solution {
public:
void bfs(const string& state, int a, int b) {
queue<string> q;
q.push(state);
vis.insert(state);
while (!q.empty()) {
string st = std::move(q.front());
q.pop();
// 两条边, 累加, 或者轮转
string tmp = st;
int n = tmp.size();
for (int i = 1; i < n; i += 2) {
char ch = (tmp[i] - '0' + a) % 10 + '0';
tmp[i] = ch;
}
if (!vis.contains(tmp)) {
vis.insert(tmp);
q.push(tmp);
}
tmp = st.substr(n - b);
tmp += st.substr(0, n - b);
if (!vis.contains(tmp)) {
vis.insert(tmp);
q.push(tmp);
}
}
return;
}
string findLexSmallestString(string s, int a, int b) {
bfs(s, a, b);
auto it = vis.begin();
return (*it);
}
set<string> vis;
};时间复杂度:,其中是字符串的长度
3397. 执行操作后不同元素的最大数量(2025.10.18)#
不难想到一个贪心思路:将数组从小到大进行排序,设排序后的数组为:
数组中可能有多个数字相同,为了尽可能让数组拥有不同元素,则应该:
关键在于当相邻的数字不同时的处理:
表面上看,应该令,但有可能大于或等于,这代表这个数字已经被使用过了,因此下一个要使用的数字应该是
因此,可以保存一个或者,当相邻两个数不同时,根据上一个数当前被映射为数字,决定当前数字应该变为多少,(注意,如果,那么变或不变都无所谓了,能变的数字肯定都出现过了)
code:
class Solution {
public:
using i64 = long long;
int maxDistinctElements(vector<int>& nums, int k) {
sort(nums.begin(), nums.end());
int n = nums.size();
i64 elem = nums[0];
i64 last = elem - k;
int cnt = 0;
for (int i = 0; i < n; i++) {
if (nums[i] != elem) {
elem = nums[i];
last = max(last, elem - k);
}
if (last <= elem + k) {
last++;
cnt++;
}
}
return cnt;
}
};时间复杂度:
2598. 执行操作后的最大MEX(2025.10.16)#
设nums.length为n,则MEX最大只能为n(当nums = [0, 1, 2, …, n-1]时)
数组中的每个元素都可以任意加上/减去value(value > 0),考虑每个元素对value的正模值x:
如果多个元素的正模值相同,则明显可以将这些元素转化为:[x, x + value, …, x + k * value],使得改变后的数组尽可能被不同的数字填充
因此,可以统计不同正模值在原数组中出现的频数,然后将其转化为上述形式(只记录在n以内的数字即可),然后遍历0~n,如果某个数不能由原数组的数转化而来,则该数即是答案
code:
class Solution {
public:
int findSmallestInteger(vector<int>& nums, int value) {
int n = nums.size();
if (value == 1) {
return n;
}
unordered_map<int, int> frequency;
vector<int> mex(n + 1, 0);
for (int i = 0; i < n; i++) {
int m = nums[i] % value;
if (m < 0) {
m += value;
}
frequency[m]++;
}
for (auto& [k, v] : frequency) {
int cnt = v;
int i = k;
while (cnt > 0) {
if (i <= n)
mex[i] = 1;
i += value;
cnt -= 1;
}
}
for (int i = 0; i < n; i++) {
if (mex[i] == 0) {
return i;
}
}
return n;
}
};时间复杂度:
3186. 施咒的最大总伤害(2025.10.11)#
先排序,很明显,当两个咒语的power值相同时,那两个咒语一定要一起选,所以合并power值相同的咒语**(以[power[i], k * power[i]]的方式,其中k代表有k个power值相同的咒语)**
处理完毕后,序列中所有咒语的power值各不相同,然后按照power值排序,设最后得到的序列为a,题目要求的是某个序列power值和的最大值,可以从动态规划集合论的角度来思考:
-
状态表示:dp[i]表示以a[i]的power值为最大power值的子序列集合(即该集合一定选择a[i]对应的咒语,并且由于a序列中power值各不相同且从小到大排序,所以dp[i]对应的集合各不相同)
-
状态属性:集合中的最大值
-
状态转移:
-
首先考虑如何划分集合,集合的相同点是子序列中最大的power值是a[i]的power值,则可以根据第二大的power值对集合进行划分,于是集合可以被划分为:
-
以a[0]的power值为最大的power值的子序列集合
-
以a[1]的power值为最大的power值的子序列集合
…
-
以a[j]的power值为最大的power值的子序列集合
其中
-
-
转移公式:
其中:
-
-
优化:由于a序列是排过序的,因此在遍历a[i]时,只需要一个下标指向,随着i的移动,判断后更新,就能实现一次遍历求出答案
code:
class Solution {
public:
using i64 = long long;
long long maximumTotalDamage(vector<int>& power) {
int n = power.size();
unordered_map<int, i64> hashmap;
for (int i = 0; i < power.size(); i++) {
hashmap[power[i]] += power[i];
}
vector<int> keys;
for (auto& [key, _] : hashmap) {
keys.push_back(key);
}
sort(keys.begin(), keys.end());
// dp[i]: 表示用power值为keys[i]的咒语集合
// 集合最大值
// max(<(keys[i] - 2)) + map(keys[i])
int m = keys.size();
vector<i64> dp(m + 1, 0);
dp[0] = hashmap[keys[0]];
i64 before = 0;
for (int i = 1, j = 0; i < m; i++) {
while (j < i && keys[j] < keys[i] - 2) {
before = max(before, dp[j]);
j++;
}
dp[i] = hashmap[keys[i]] + before;
}
i64 res = 0;
for (int i = 0; i < m; i++) {
res = max(res, dp[i]);
}
return res;
}
};时间复杂度:
1488. 避免洪水泛滥(2025.10.7)#
- 从左到右遍历抽干日, 对于一个抽干日,其可能有多个湖泊进行选择,将这些可选择的湖泊(第i个可选择的湖泊)上次下雨和该次下雨时间记为,按照贪心的思想,应该将其按照从小到大进行排序,即越早可能泛洪的湖泊应该更早被抽水,更大的湖泊可以尽可能的交给后面的抽干日去处理
但是固定抽干日,排序该日可选择的不同湖泊在代码实现上比较困难,于是可以考虑换一个角度,固定湖泊,找寻可选择的抽干日:
- 从左到右遍历湖泊时,假设湖泊会发生洪水,根据其上一次的下雨时间和本次下雨时间,找寻内的抽干日,假设这些抽干日有个,将其从小到大进行排列,根据贪心思想,应该选择距离最近的抽干日,而越晚的抽干日,灵活性越大,可以用于抽干更晚装满的湖,即越晚的抽水日应该留到后面给更大的湖泊使用
以上两种贪心思想等价,但是第二种在代码实现上更简单:利用哈希表记录每个湖泊上次的下雨时间,并将所有的抽干日存储到set中,然后遍历下雨日,在set中找到第一个的抽干日,并判断其是否合法即可
code:
class Solution {
public:
vector<int> avoidFlood(vector<int>& rains) {
int n = rains.size();
vector<int> ans(n, -1);
unordered_map<int, int> last_rain;
set<int> dry_days;
for (int i = 0; i < n; i++) {
if (rains[i] == 0) {
dry_days.insert(i);
}
}
for (int i = 0; i < n; i++) {
if (rains[i] > 0) {
if (last_rain.contains(rains[i])) {
int j = last_rain[rains[i]];
// > j的第一个, 要用set的upper_bound方法, algorithm的方法会退化为线性时间
auto it = dry_days.upper_bound(j);
// 必须在第i天之前
if (it == dry_days.end()) return {};
if ((*it) >= i) return {};
ans[(*it)] = rains[i];
dry_days.erase(it);
}
last_rain[rains[i]] = i;
}
}
// 如果抽干日比下雨日更多,选择湖泊1
for (int i = 0; i < n; i++) {
if (rains[i] == 0 && ans[i] == -1) {
ans[i] = 1;
}
}
return ans;
}
};时间复杂度:
778. 水位上升的泳池中游泳(2025.10.6)#
题目提到在方格之间移动不花费时间,求最小的时间t,使得能从(0, 0)移动到(n-1, n-1)
答案t一定有上下界(因为格子中的数值有限),下界为0,上界为,那么可以考虑二分答案:
- 二分答案t
- 判断水位为t时,能否从(0, 0)到(n - 1, n - 1)
- 如果可以,记录答案,减小上界
- 否则,增大下界
从(0, 0)进行BFS,根据当前水位,可以判断能否到达(n-1, n-1)
code:
class Solution {
public:
bool bfs(queue<pair<int, int>> &q, vector<vector<int>> &grid, int t) {
int m = grid.size();
int n = grid[0].size();
vector<vector<int>> vis(m, vector<int>(n, 0));
if (grid[0][0] > t) return false;
q.push({0, 0});
vis[0][0] = 1;
while (!q.empty()) {
auto point = q.front();
q.pop();
int h = max(t, grid[point.first][point.second]);
for (int i = 0; i < 4; i++) {
int nx = point.first + dx[i];
int ny = point.second + dy[i];
if (nx < 0 || nx >= m || ny < 0 || ny >= n || vis[nx][ny] != 0 || h < grid[nx][ny])
continue;
vis[nx][ny] = 1;
q.push({nx, ny});
}
}
return vis[m - 1][n - 1] == 1;
}
int swimInWater(vector<vector<int>>& grid) {
int n = grid.size();
queue<pair<int, int>> q;
int l = INT_MAX, r = INT_MIN;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
l = min(l, grid[i][j]);
r = max(r, grid[i][j]);
}
}
int ans = -1;
while (l <= r) {
int mid = l + (r - l) / 2;
if (bfs(q, grid, mid)) {
r = mid - 1;
ans = mid;
} else {
l = mid + 1;
}
}
return ans;
}
constexpr static int dx[] = {0, 0, 1, -1};
constexpr static int dy[] = {1, -1, 0, 0};
};时间复杂度:
417. 太平洋大西洋水流问题(2025.10.5)#
可以把二维矩阵看做一个图,单元格抽象为点,设高度为,针对两个相邻单元格,,其对应的高度为,,如果有,则从向连接一条边。
题目要求出能够流向PO和AO的单元格,一种想法是在原先的二维矩阵上围上一圈结点,并设置这些结点的属性(标识不同的海洋),然后从每个结点开始BFS遍历,只要其能够同时到达拥有两种属性的结点,该结点就符合题意,时间复杂度为,其中,是结点个数,是边数,在本题中都是数量级,用于通过题目显然不现实。
可以反向思考,从PO和AO向单元格开始流,只需要翻转一下原先边的方向:
- 显然,第一行第一列是PO能够流向的结点,将这些结点塞入队列,进行一次BFS,就能知道有哪些结点可以流向PO
- 同理,最后一行最后一列是AO能流向的结点,同样一次BFS,能知道有哪些结点可以流向AO
- 对于上面求得的两个集合,做一个交集,就是既能流向PO,也能流向AO的结点
code:
class Solution {
public:
void bfs(queue<pair<int, int>> &q, vector<vector<int>>& heights, vector<vector<int>>& vis) {
int m = heights.size();
int n = heights[0].size();
while (!q.empty()) {
auto point = q.front();
q.pop();
int h = heights[point.first][point.second];
for (int i = 0; i < 4; i++) {
int nx = point.first + dx[i];
int ny = point.second + dy[i];
if (nx < 0 || nx >= m || ny < 0 || ny >= n || vis[nx][ny] == 1 || heights[nx][ny] < h)
continue;
vis[nx][ny] = 1;
q.push({nx, ny});
}
}
}
vector<vector<int> > pacificAtlantic(vector<vector<int> > &heights) {
int m = heights.size();
int n = heights[0].size();
vector<vector<int>> pacific_vis(m, vector<int>(n, 0));
vector<vector<int>> altantic_vis(m, vector<int>(n, 0));
queue<pair<int, int>> q_pacific, q_altantic;
for (int i = 0; i < n; i++) {
pacific_vis[0][i] = 1;
q_pacific.push({0, i});
altantic_vis[m - 1][i] = 1;
q_altantic.push({m - 1, i});
}
for (int i = 0; i < m; i++) {
if (pacific_vis[i][0] == 0) {
pacific_vis[i][0] = 1;
q_pacific.push({i, 0});
}
if (altantic_vis[i][n - 1] == 0) {
altantic_vis[i][n - 1] = 1;
q_altantic.push({i, n - 1});
}
}
bfs(q_pacific, heights, pacific_vis);
bfs(q_altantic, heights, altantic_vis);
vector<vector<int>> ans;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (pacific_vis[i][j] && altantic_vis[i][j]) {
ans.push_back({i, j});
}
}
}
return ans;
}
constexpr static int dx[] = {-1, 1, 0, 0};
constexpr static int dy[] = {0, 0, 1, -1};
};时间复杂度:,其中,,(是一个常数)
11. 盛最多水的容器(2025.10.4)#
不妨先考虑只有两条线,那么根据短板效应,两条线中高度最短的那个决定了水的高度:
考虑向中间插入一条线(长或短):
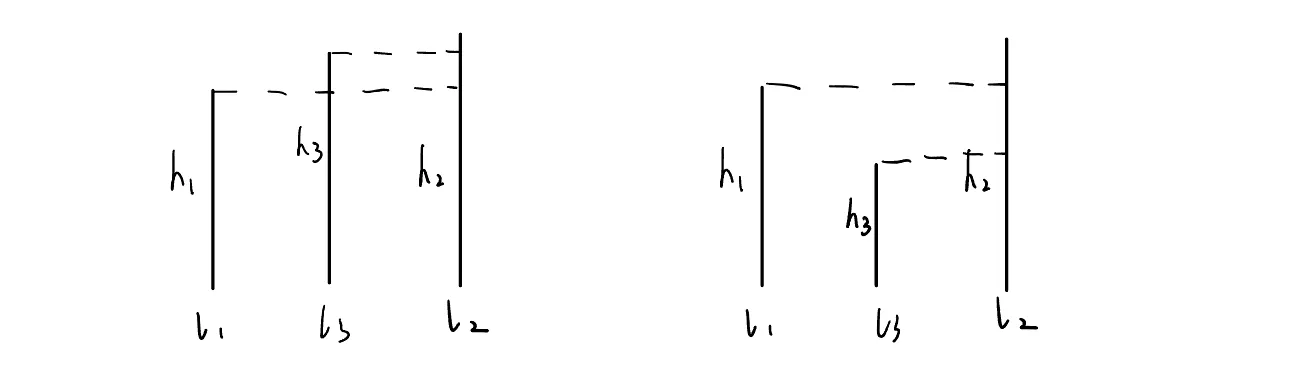
分析如下:
考虑,中较短的那条线(假设是),由于在右端点,设在和之间的为,则显然与组成的容器容量不会超过与组成的容器容量
于是可以跳过中间这部分的计算,直接向右移动
同理,如果较短,向左移动,直到
每移动一次,就计算一次容量,并保存最大容量
code:
class Solution {
public:
int maxArea(vector<int>& height) {
int l = 0, r = static_cast<int>(height.size()) - 1;
int ans = 0;
while (l < r) {
ans = max(ans, min(height[l], height[r]) * (r - l));
if (height[l] < height[r]) {
l++;
} else {
r--;
}
}
return ans;
}
};时间复杂度:
42. 接雨水#
407. 接雨水 II(2025.10.3)#
该题不能向接雨水一样使用单调栈来做(不能遍历所有的行和列然后取能接雨水的最小值)
但同样可以考虑木桶效应(因为最外面一圈格子不可能存下雨水),接雨水考虑的是一维中左右两端的木板,本题是二维,则考虑上下左右四端的木板。根据木桶效应,桶中能装多少水由最短的那块木板,那么应该从四端最短的木板找起,由于其是最短的木板,设其高度为,那么:
- 如果与其相邻的格子是木板,不做处理
- 如果与其相邻的格子不是木板, 考虑其高度:
- 如果,那么该格子保存不了雨水,并且由于其比木板更高,原先的木板就没用了,该格子会代替原木板变为高度为的木板。
- 如果,那么该格子能够保存单位的雨水,将这些雨水加入后,该格子不会能够接更多的雨水了,可以将其看做新的高度为的木板,以此来维护新的木桶。
可以使用最小堆来保存四周的木板高度,然后从最低的木板开始遍历,直到堆为空,中保存的是收集雨水的总和
code:
class Solution {
public:
struct Point {
int x;
int y;
int h;
friend bool operator > (const Point& lhs, const Point& rhs) {
return lhs.h > rhs.h;
}
};
int trapRainWater(vector<vector<int>>& heightMap) {
int m = heightMap.size();
int n = heightMap[0].size();
if (m < 3 || n < 3) return 0;
vector<int> visited((m + 1) * (n + 1), 0);
priority_queue<Point, vector<Point>, greater<>> heap;
auto arrMap = [n](int i, int j) -> int {
return i * n + j;
};
heap.push({0, 0, heightMap[0][0]}); visited[arrMap(0, 0)] = 1;
heap.push({0, n - 1, heightMap[0][n - 1]}); visited[arrMap(0, n - 1)] = 1;
heap.push({m - 1, 0, heightMap[m - 1][0]}); visited[arrMap(m - 1, 0)] = 1;
heap.push({m - 1, n - 1, heightMap[m - 1][n - 1]}); visited[arrMap(m - 1, n - 1)] = 1;
for (int i = 1; i < n - 1; i++) {
heap.push({0, i, heightMap[0][i]}); visited[arrMap(0, i)] = 1;
heap.push({m - 1, i, heightMap[m - 1][i]}); visited[arrMap(m - 1, i)] = 1;
}
for (int j = 1; j < m - 1; j++) {
heap.push({j, 0, heightMap[j][0]}); visited[arrMap(j, 0)] = 1;
heap.push({j, n - 1, heightMap[j][n - 1]}); visited[arrMap(j, n - 1)] = 1;
}
int remain = m * n - (2 * m + 2 * n - 4);
int ans = 0;
while (remain > 0) {
auto p = heap.top();
heap.pop();
for (int i = 0; i < 4; i++) {
int nx = p.x + dx[i], ny = p.y + dy[i];
if (nx >= 0 && nx < m && ny >= 0 && ny < n) {
if (visited[arrMap(nx, ny)]) continue;
int h = heightMap[nx][ny];
visited[arrMap(nx, ny)] = 1;
remain--;
if (h >= p.h) {
heap.push({nx, ny, h});
} else {
ans += p.h - h;
heap.push({nx, ny, p.h});
}
}
}
}
return ans;
}
constexpr static int dx[] = {0, 0, 1, -1};
constexpr static int dy[] = {1, -1, 0, 0};
};时间复杂度:二维矩阵行列,时间复杂度为
1546. 和为目标值且不重叠的非空子数组的最大值(2025.10.2)#
子数组是连续的,所以题目要求连续子序列和为target的最大数量(连续子序列相互不重叠),于是可以抽象为以下模型(假设一条线代表从i到j的子序列和为target):
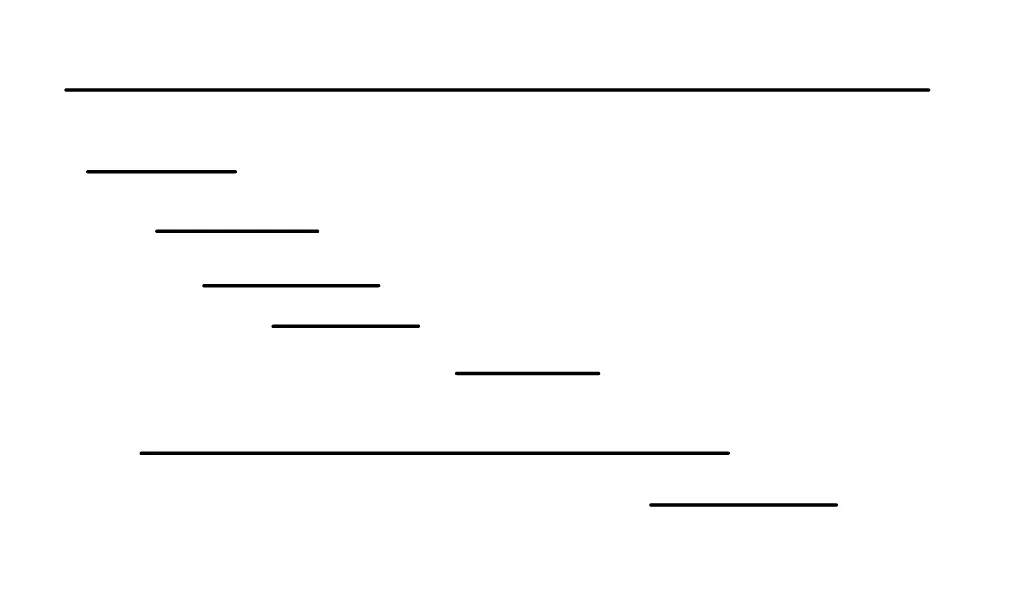
该模型即求出最多的不相交的线段数量线段覆盖 ↗
根据贪心算法,将所有的线段以[start, end]的形式表示,根据end从小到大进行排序,然后依次遍历选择,即哪个线段在前就先选哪个
对应的本题,从头遍历nums数组,对于一个数nums[i],如果能找到一个start,使得[start, i]的和为target,就将序列数+1,问题的关键在于如何求start坐标
可以使用前缀和,当遍历nums时,同时记录前缀和sums,如果存在start,则sums[i] - sums[start - 1] = target
即sums[start - 1] = sums[i] - target
将前缀和用哈希表保存即可快速搜寻sums[start - 1]
code:
class Solution {
public:
int maxNonOverlapping(vector<int>& nums, int target) {
int ans = 0;
int i = 1;
int n = nums.size();
vector<int> sum(n + 1, 0);
while (i <= n) {
unordered_set<int> s;
s.insert(0);
while (i <= n) {
sum[i] = sum[i - 1] + nums[i - 1];
if (s.contains(sum[i] - target)) {
ans++;
break;
}
s.insert(sum[i]);
i += 1;
}
if (i > n) break;
sum[i] = 0;
i = i + 1;
}
return ans;
}
};时间复杂度:
1948. 删除系统中的重复文件夹(2025.9.30)#
很容易想到使用Trie结构保存结点,再利用哈希表存储每个结点的子树结构,在遍历树时,如果不同节点有相同的子树结构,就将这些结点删去
问题在于如何用哈希表存储每个结点的子树结构:
一个方法是将一个结点的子树映射为相同的字符串,这需要做到
- 字符串需要包含子树所有节点的文件夹名
- 字符串要能够表达结点的父子关系
考虑针对某一个结点,对其子节点的遍历过程,将向下递的动作用一个非字母字符表示,向上归的动作用另一个非字母字符表示,就可以描述一颗树的形状,比如x结点有两个叶子节点y,z,可以表示为x(y)(z)
一般的,定义如下括号表达式:
-
对于叶子结点,设其文件名为S,则其括号表达式为S
-
对于任意子树x,设x的儿子为y1,y2,…,则子树x的括号表达式为:
x文件夹名 + (子树y1的表达式) + (子树y2的表达式) + ... -
为了括号表达式的唯一性,在求出y1,y2,…的表达式后,对这些表达式进行排序再拼接,就可以避免下面这种情况(子树相同但表达式不同)
shellx x / \ / \ y z z y
代码流程:
-
构建字典树
-
生成每个结点的括号表达式:
先将每个结点的子树表达式拼接(即
(子树y1的表达式) + (子树y2的表达式) + ...),记录到哈希表中- 如果该表达式是首次生成,将表达式和对应的子树根节点x保存到哈希表中
- 否则文件夹出现重复,把当前根节点x和哈希表中记录的根节点都标记为删除
-
DFS遍历Trie树,仅遍历未被删除的结点,同时记录路径上的文件夹名
code:
class Solution {
public:
struct Node {
Node() :name(""), deleted(false) {}
Node(string ne) : name(ne), deleted(false) {}
~Node() {
clear();
}
void clear() {
for (auto it = children.begin(); it != children.end(); it++) {
if (it->second) {
it->second->clear();
delete it->second;
}
it->second = nullptr;
}
}
string name;
unordered_map<string, Node*> children;
bool deleted;
};
void constructTrie(Node *node, vector<string> &path) {
for (string name : path) {
if (!node->children.contains(name)) {
node->children[name] = new Node(name);
}
node = node->children[name];
}
}
string generateHash(unordered_map<string, Node*> &hash, Node *root) {
if (root == nullptr) {
return "";
}
if (root->children.empty()) {
return root->name;
}
string res("");
vector<string> sub_hash;
for (auto&& child : root->children) {
sub_hash.push_back("(" + generateHash(hash, child.second) + ")");
}
sort(sub_hash.begin(), sub_hash.end());
for (auto&& sub_hash : sub_hash) {
res += sub_hash;
}
// compare
if (hash.contains(res)) {
root->deleted = true;
hash[res]->deleted = true;
} else {
hash[res] = root;
}
res = root->name + res;
return res;
}
void dfs(Node* root, vector<string> &path, vector<vector<string>> &res) {
if (root == nullptr || root->deleted) {
return;
}
path.push_back(root->name);
res.push_back(path);
for (auto&& child : root->children) {
if (!child.second->deleted)
dfs(child.second, path, res);
}
path.pop_back();
}
vector<vector<string>> deleteDuplicateFolder(vector<vector<string>>& paths) {
Node* node = new Node("/");
for (auto &&path : paths) {
constructTrie(node, path);
}
unordered_map<string, Node*> hash;
generateHash(hash, node);
vector<vector<string>> res;
vector<string> path;
for (auto&& child : node->children) {
dfs(child.second, path, res);
}
delete node;
return res;
}
};1039. 多边形三角剖分的最低得分(2025.9.29)#
该题的考点是区间动态规划,仍然从集合的角度来分析
-
状态表示:dp[l, r]表示由边(l, l + 1), (l + 1, l + 2),…,(r - 1, r),(r, l)组成的多边形被剖分成不同的三角形集合
-
状态属性:集合中乘积和的最小值
-
状态转移:
-
首先考虑如何划分集合:
由于多边形最后最划分为多个三角形,那么多边形的边都是各个三角形的边,我们以(r, l)这条边隶属于哪个三角形来划分集合:
(r, l)的两个端点l, r, 只需要再加一个端点就可以组成三角形,设端点为k,则k = l + 1, … r - 1
于是由k和边(r, l)组成的三角形将原多边形划分为了三个部分:
- [l, k]:以(l, l + 1),…,(k, l)边组成的新多边形
- [k, r]:以(k, k + 1),…,(r, k)边组成的新多边形
- k&(r, l):以点k和边(r, l)组成的三角形
- 于是状态转移公式:
-
为什么选择(r, l)边作为三角形的一个边处理?
因为状态表示中无法直接涉及到(r, l),而直接使用(r, l)边的三角形又能够将集合划分为不同的部分来完成状态的转移
code:
class Solution {
public:
int minScoreTriangulation(vector<int>& values) {
constexpr int N = 50;
constexpr int INF = 0x3f3f3f3f;
vector<vector<int>> dp(N, vector<int>(N, INF));
int n = values.size();
for (int i = 0; i < n; i++) {
dp[i][i] = 0;
if (i + 1 < n) {
dp[i][i + 1] = 0;
}
}
for (int len = 2; len < n; len++) {
for (int l = 0; l < n; l++) {
int r = l + len;
if (r >= n) continue;
// k: l + 1 -> r - 1
for (int k = l + 1; k < r; k++) {
dp[l][r] = min(dp[l][r],
dp[l][k] + dp[k][r] + values[l] * values[k] * values[r]);
}
}
}
return dp[0][n - 1];
}
};时间复杂度:
2040. 两个有序数组的第K小乘积(2025.9.28)#
直接枚举显然是不现实的,注意到两个数组的乘积值域在之间
因此可以考虑对答案进行二分:
对于一个数mid,设两个数组的乘积中小于mid的数有cnt个,那么:
cnt < k,则mid有可能是答案,提高答案的下界cnt >= k,则mid不可能是答案,降低答案的上界
于是问题转化为如何求两个数组的乘积中小于mid的个数
二分#
由nums1 × nums2 < mid(nums1不为0),得:
nums2 < mid / nums1(nums1 > 0)nums2 > mid / nums1(nums1 < 0)
两个数组都是排好序的,所以在遍历第一个数组的时候,利用二分求出小于/大于目标数的数字有多少个即可
code:
class Solution {
public:
using i64 = long long;
bool check(vector<int>& nums1, vector<int> &nums2, i64 k, i64 num) {
// 找nums1 * nums2中,< num的个数cnt,与k比较
// cnt < k -> true
// cnt >= k -> false
i64 cnt = 0;
for (int n1 : nums1) {
if (n1 == 0) {
if (num > 0) cnt += nums2.size();
continue;
}
i64 n2 = num / n1;
auto up_it = upper_bound(nums2.begin(), nums2.end(), n2);
auto low_it = lower_bound(nums2.begin(), nums2.end(), n2);
if (n1 > 0) {
int d1 = distance(nums2.begin(), low_it);
int d2 = distance(nums2.begin(), up_it);
if (num > 0 && num % n1 != 0) {
cnt += max(0, d2);
} else {
cnt += max(0, d1);
}
} else {
int d1 = distance(low_it, nums2.end());
int d2 = distance(up_it, nums2.end());
if (num > 0 && num % n1 != 0) {
cnt += max(0, d1);
} else {
cnt += max(0, d2);
}
}
}
return cnt < k;
}
long long kthSmallestProduct(vector<int>& nums1, vector<int>& nums2, long long k) {
i64 low = min({1ll * nums1.front() * nums2.front(), 1ll * nums1.front() * nums2.back(),
1ll * nums1.back() * nums2.front(), 1ll * nums1.back() * nums2.back()});
i64 high = max({1ll * nums1.front() * nums2.front(), 1ll * nums1.front() * nums2.back(),
1ll * nums1.back() * nums2.front(), 1ll * nums1.back() * nums2.back()});
i64 ans = 0;
while (low <= high) {
i64 mid = (low + high) >> 1;
if (check(nums1, nums2, k, mid)) {
low = mid + 1;
ans = mid;
} else {
high = mid - 1;
}
}
return ans;
}
};时间复杂度:
矩阵#
数组单增,负数正数同时存在,我们可以将分界线列出,假设:
nums1[0~pos1]是负数,nums1[pos1~n1]是正数nums2[0~pos2]是负数,nums1[pos1~n2]是正数
将nums1[0~pos1]与nums2[0~pos2]各个数分别相乘,观察性质(以两个数组中元素都大于0为例):
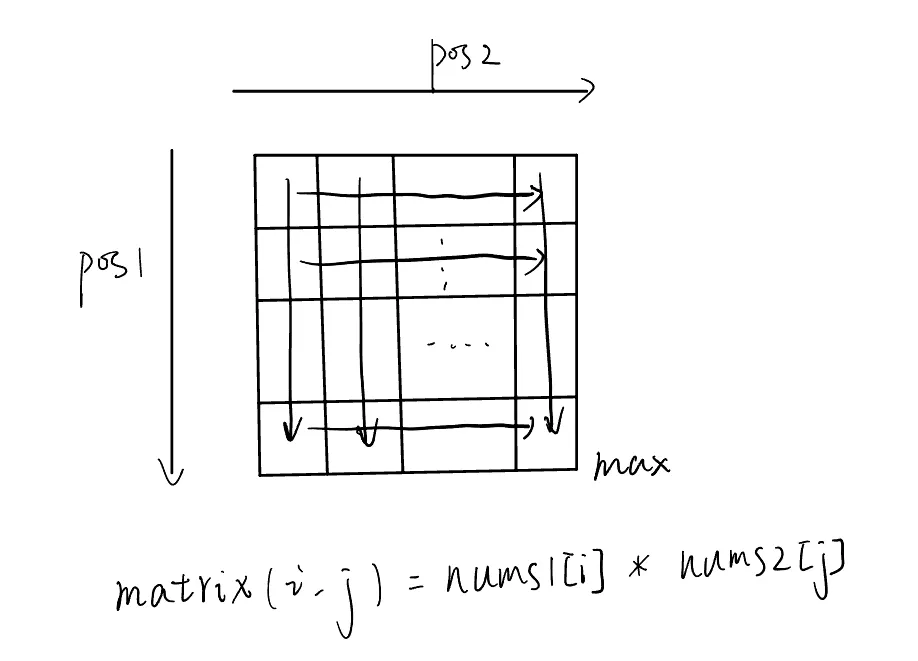
不难发现,左上角是最小值,随行增加,随列增加,右下角为最大值,之后求该矩阵中小于mid的个数,参考leetcode-240 ↗
具体做法是利用双指针,指向矩阵右上角的坐标,计算矩阵中对应的位置元素,如果该元素大于等于mid,向左移动,否则向下移动,直到找到最后一个小于mid的元素,移动的过程中,每找到一个小于mid的元素,就累加该行的个数
code:
class Solution {
public:
using i64 = long long;
bool check(vector<int>& nums1, vector<int> &nums2, i64 k, i64 num) {
// 找nums1 * nums2中,< num的个数cnt,与k比较
// cnt < k -> true
// cnt >= k -> false
i64 cnt = 0;
for (int i = 0, j = pos2; i <= pos1 && j >= 0;) {
if (1ll * nums1[i] * nums2[j] >= num) {
i++;
}
else {
cnt += (pos1 - i + 1);
j--;
}
}
for (int i = 0, j = pos2 + 1; i <= pos1 && j < nums2.size();) {
if (1ll * nums1[i] * nums2[j] >= num) {
j++;
} else {
cnt += (nums2.size() - j);
i++;
}
}
for (int i = pos1 + 1, j = 0; i < nums1.size() && j <= pos2;) {
if (1ll * nums1[i] * nums2[j] >= num) {
i++;
} else {
cnt += (nums1.size() - i);
j++;
}
}
for (int i = pos1 + 1, j = nums2.size() - 1; i < nums1.size() && j > pos2;) {
if (1ll * nums1[i] * nums2[j] >= num) {
j--;
} else {
cnt += (j - pos2);
i++;
}
}
return cnt < k;
}
long long kthSmallestProduct(vector<int>& nums1, vector<int>& nums2, long long k) {
i64 low = min({1ll * nums1.front() * nums2.front(), 1ll * nums1.front() * nums2.back(),
1ll * nums1.back() * nums2.front(), 1ll * nums1.back() * nums2.back()});
i64 high = max({1ll * nums1.front() * nums2.front(), 1ll * nums1.front() * nums2.back(),
1ll * nums1.back() * nums2.front(), 1ll * nums1.back() * nums2.back()});
i64 ans = 0;
for (int i = 0; i < nums1.size(); i++) {
if (nums1[i] < 0) pos1 = i;
}
for (int i = 0; i < nums2.size(); i++) {
if (nums2[i] < 0) pos2 = i;
}
while (low <= high) {
i64 mid = (low + high) >> 1;
if (check(nums1, nums2, k, mid)) {
low = mid + 1;
ans = mid;
} else {
high = mid - 1;
}
}
return ans;
}
private:
int pos1{-1};
int pos2{-1};
};时间复杂度:
976. 三角形的最大周长(2025.9.28)#
枚举三条边a,b,c,三角形三边需要满足:
- a + b > c
- a + c > b
- b + c > a
如果按边大小排序,设c >= b >= a,能简化为一个条件:
- a + b > c
将边从大到小排序,在枚举一个最长边nums[i] = c时,能使得三角形周长最大的合法集合只能为nums[i], nums[i + 1], nums[i + 2]
- 如果nums[i], nums[i + 1], nums[i + 2]合法,则三条边组成的三角形周长最大
- 如果不合法,那么以nums[i] = c作为最长边将不能和nums[i + 3]及之后的边组成三角形
code:
class Solution {
public:
int largestPerimeter(vector<int>& nums) {
sort(nums.begin(), nums.end(), greater<>());
int ans = 0;
for (int i = 2; i < nums.size(); i++) {
// a <= b <= c
int a = nums[i], b = nums[i - 1], c = nums[i - 2];
if (c < a + b) {
ans = a + b + c;
break;
}
}
return ans;
}
};时间复杂度:
812. 最大三角形面积(2025.9.27)#
枚举三个点A,B,C,设三条边的边长为a,b,c
根据海伦公式(或者用余弦定理)得出:
其中,
注意,如果三个点x坐标或y坐标相同,三角形不合法
code:
class Solution {
public:
double getDistance(int x1, int y1, int x2, int y2) {
double d2 = pow(x1 - x2, 2) + pow(y1 - y2, 2);
return sqrt(d2);
}
double largestTriangleArea(vector<vector<int>>& points) {
int n = points.size();
double ans = INT_MIN;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
for (int k = j + 1; k < n; k++) {
auto &pi = points[i];
auto &pj = points[j];
auto &pk = points[k];
if (pi[0] == pj[0] && pi[0] == pk[0]) continue;
if (pi[1] == pj[1] && pi[1] == pk[1]) continue;
double a = getDistance(pi[0], pi[1], pj[0], pj[1]);
double b = getDistance(pi[0], pi[1], pk[0], pk[1]);
double c = getDistance(pj[0], pj[1], pk[0], pk[1]);
double sum = (a + b + c) / 2;
ans = max(ans, sqrt(sum * (sum - a) * (sum - b) * (sum - c)));
}
}
}
return ans;
}
};时间复杂度:
611. 有效三角形的个数(2025.9.26)#
排序 + 二分#
将边长度按从小到大排序
因为需要三条边,无论如何都要枚举两条边a,b,不妨从小到大进行枚举(即a <= b)
设第三条边为c,那么c需要满足:
a + b > ca + c > bb + c > a
在枚举c的过程中,为了避免重复,c必须满足c >= b
故上述条件简化为:
a <= b <= ca + b > c
设a,b对应的下标分别为i,j,那么c的下标范围是:
[l, r] = [j + 1, lower_bound(nums.begin() + j + 1, nums.end(), a + b)]
,如果r < l,则没有与a,b对应的c存在
code:
class Solution {
public:
int triangleNumber(vector<int>& nums) {
// 枚举a, b
// c: a + b > c, a + c > b, b + c > a
// -> c < a + b && c > b - a && c > a - b
sort(nums.begin(), nums.end());
int ans = 0;
for (int i = 0; i < nums.size(); i++) {
for (int j = i + 1; j < nums.size(); j++) {
int k = j + 1;
int start = max(nums[j] - nums[i], nums[i] - nums[j]);
int end = nums[i] + nums[j];
auto l = upper_bound(nums.begin() + k, nums.end(), start);
auto r = lower_bound(nums.begin() + k, nums.end(), end);
if (r - l < 0) continue;
ans += (r - l);
}
}
if (ans < 0) ans = 0;
return ans;
}
};时间复杂度:
排序 + 双指针#
二分的代码不难发现一个规律:枚举a,b后,寻找c时,只需要找到满足c < a + b的最大的c
换句话说,对于前一个b,有c < a + b,对于下一个b,也有可能有c < a + b
因此,我们只需要维护c所在区间的最大值下标
条件是:只要c < a + b,就让c的下标右移
c所在区间的最小值下标一定是b的下标+1
于是可以采用双指针,在枚举b的同时,维护c当前可能的最大值下标
code:
class Solution {
public:
int triangleNumber(vector<int>& nums) {
// 枚举a, b
// c: a + b > c
// a <= b <= c
sort(nums.begin(), nums.end());
int ans = 0;
for (int i = 0; i < nums.size(); i++) {
for (int j = i + 1, k = j + 1; j < nums.size(); j++) {
// k是c合法范围内的最大值下标
k = max(k, j + 1);
int end = nums[i] + nums[j];
while (k < nums.size() && nums[k] < end) {
k++;
}
ans += max(0, k - j - 1);
}
}
return ans;
}
};时间复杂度:
120. 三角形最小路径和(2025.9.25)#
三角形dp,从集合的角度分析:
-
状态表示:dp(i, j):从triangle(0, 0)走到(i, j)的不同路径组成的集合
-
状态计算:集合中路径总和的最小值
-
状态转移:根据路径中的最后一次转移来划分集合
-
从(i - 1, j)走到(i, j)
-
从(i - 1, j - 1)走到(i, j)
-
转移公式:
-
-
优化:注意到在计算dp(i, …)时,只需要dp(i - 1, …),所以可以将状态优化为1维数组,在计算状态时只保留上一层的状态dp(j)
code:
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
int ans = INT_MAX;
vector<int> dp(triangle.size(), INT_MAX / 2);
dp[0] = triangle[0][0];
for (int i = 1; i < triangle.size(); i++) {
for (int j = triangle[i].size() - 1; j >= 0; j--) {
int old_dp = INT_MAX / 2;
if (j >= 1) old_dp = dp[j - 1];
dp[j] = min(dp[j], old_dp) + triangle[i][j];
}
}
for (int i = 0; i < dp.size(); i++) {
ans = min(ans, dp[i]);
}
return ans;
}
};时间复杂度:
166. 分数到小数(2025.9.24)#
问题的难度在于如何判定循环小数的范围
使用长除法观察示例:
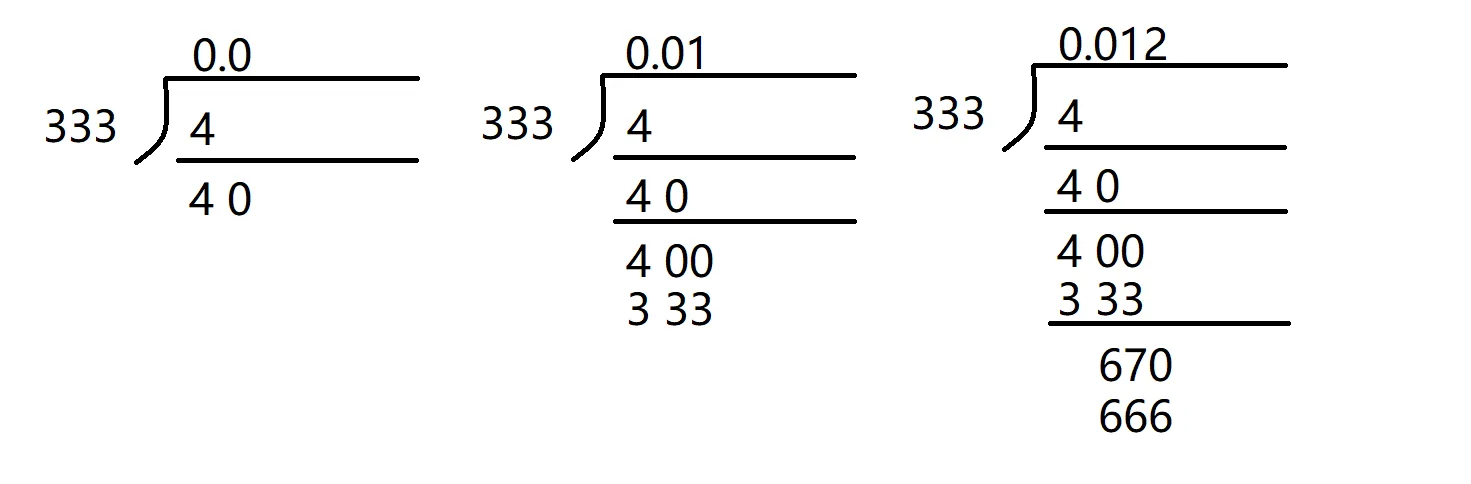
- 小数点后第1位为0时,对应的被除数为40
- 小数点后第2位为1时,对应的被除数为400
- 小数点后第3位为2时,对应的被除数为670
以此类推…, 小数点后第4位开始循环,对应的被除数为40
不难发现,当小数点后开始循环时,对应的被除数一定已经出现过,可以使用哈希表来保存出现过的被除数,当一个被除数重复出现时,说明有循环小数并已经开始循环
于是问题来到了如何判断哪一部分是循环小数,我们可以通过存储下面两个信息来解决:
- 小数点后第k位对应的被除数
- 小数点后当前的总位数n
当被除数重复时,小数点后第k位~第n位就是循环小数所在的部分,前者可以用hashmap解决,后者可以开辟一个额外变量来记录
由于题目中分子,分母的范围在[INT_MIN, INT_MAX],所以在计算时最好使用long long,同时将小数点前和小数点后的计算分开,更加清晰
code:
class Solution {
public:
using i64 = long long;
void transform_quotient(string &ans, i64 quotient) {
string res("");
while (quotient > 0) {
int mod = quotient % 10;
quotient /= 10;
res += static_cast<char>(mod + '0');
}
if (res.size() == 0) return;
for (int i = res.size() - 1; i >= 0; i--) {
ans += res[i];
}
}
string fractionToDecimal(int numerator, int denominator) {
bool neg1 = numerator < 0;
bool neg2 = denominator < 0;
i64 numerator1 = abs(numerator * 1ll);
i64 denominator1 = abs(denominator * 1ll);
string ans("");
// 小数点前
if (numerator1 >= denominator1) {
while (numerator1 >= denominator1) {
i64 quotient = numerator1 / denominator1;
numerator1 %= denominator1;
transform_quotient(ans, quotient);
}
} else {
ans += '0';
}
// 小数点后
if (numerator1 != 0){
ans += '.';
int index = ans.size();
vector<int> cycle;
unordered_map<int, int> hash;
while (true) {
numerator1 *= 10;
if (hash.contains(numerator1)) {
int st = hash[numerator1];
string tmp = ans.substr(0, cycle[st]) + '(';
for (int i = cycle[st]; i < ans.size(); i++) {
tmp += ans[i];
}
tmp += ')';
ans = tmp;
break;
}
int quotient = numerator1 / denominator1;
cycle.push_back(index);
hash[numerator1] = cycle.size() - 1;
index++;
numerator1 %= denominator1;
ans += static_cast<char>(quotient + '0');
if (numerator1 == 0) {
break;
}
}
}
if (neg1 != neg2 && numerator != 0) {
ans = "-" + ans;
}
return ans;
}
};时间复杂度:设小数点后位数数量级为n,代码时间复杂度为